ANOVA galima rinktis tokiu atveju, kai turime 3 arba daugiau kategorijų. Sužinokite, kaip atlikti ir interpretuoti ANOVA testą.
Author
Paulius Alaburda
Published
April 15, 2023
Kaip rinktis ANOVA?
Kada rinktis ANOVA?
ANOVA galima rinktis tokiu atveju, kai turime 3 arba daugiau kategorijų nepriklausomame kintamajame, pagal kurias norime palyginti tolydų priklausomą kintamąjį. Pavyzdžiui, norime palyginti, ar gerklės skausmo lygis skyrėsi priklausomai nuo to, ar buvo atlikta mažos, vidutinės ar didelės apimties operacija. Tokių atvejų pasitaiko dažnai, bet ne kiekvienas žino, ką daryti, jeigu ANOVA rezultatas yra statistiškai reikšmingas.
Vienpusė ANOVA
Vienpusė ANOVA reiškia, jog turime tolydų kintamąjį (ūgį, svorį, amžių) ir jų norime palyginti tarp 3 arba daugiau grupių.
Dvipusė ANOVA naudojama, kai norime įvertinti dviejų nepriklausomų kintamųjų poveikį priklausomam kintamajam.
Post-hoc testai
Jeigu mūsų ANOVA rezultatas buvo statistiškai reikšmingas, vis dar nežinome, kuri pora grupių tarpusavyje turėtų statistiškai reikšmingą skirtumą. Tam turime atlikti post-hoc testą, t.y. testą, kuris parenka 2 subgrupes ir konkrečiai jas palygina.
Nėra vieno standarto, kaip būtinai reikia atlikti post-hoc testą, bet dažniausias pasirinkimas yra Tukey HSD (Honestly Significant Difference) testas. Su R tai galima atlikti naudojantis TukeyHSD funkcija:
TukeyHSD(my.anova)
Tukey multiple comparisons of means
95% family-wise confidence level
Fit: aov(formula = Sepal.Length ~ Species, data = iris)
$Species
diff lwr upr p adj
versicolor-setosa 0.930 0.6862273 1.1737727 0
virginica-setosa 1.582 1.3382273 1.8257727 0
virginica-versicolor 0.652 0.4082273 0.8957727 0
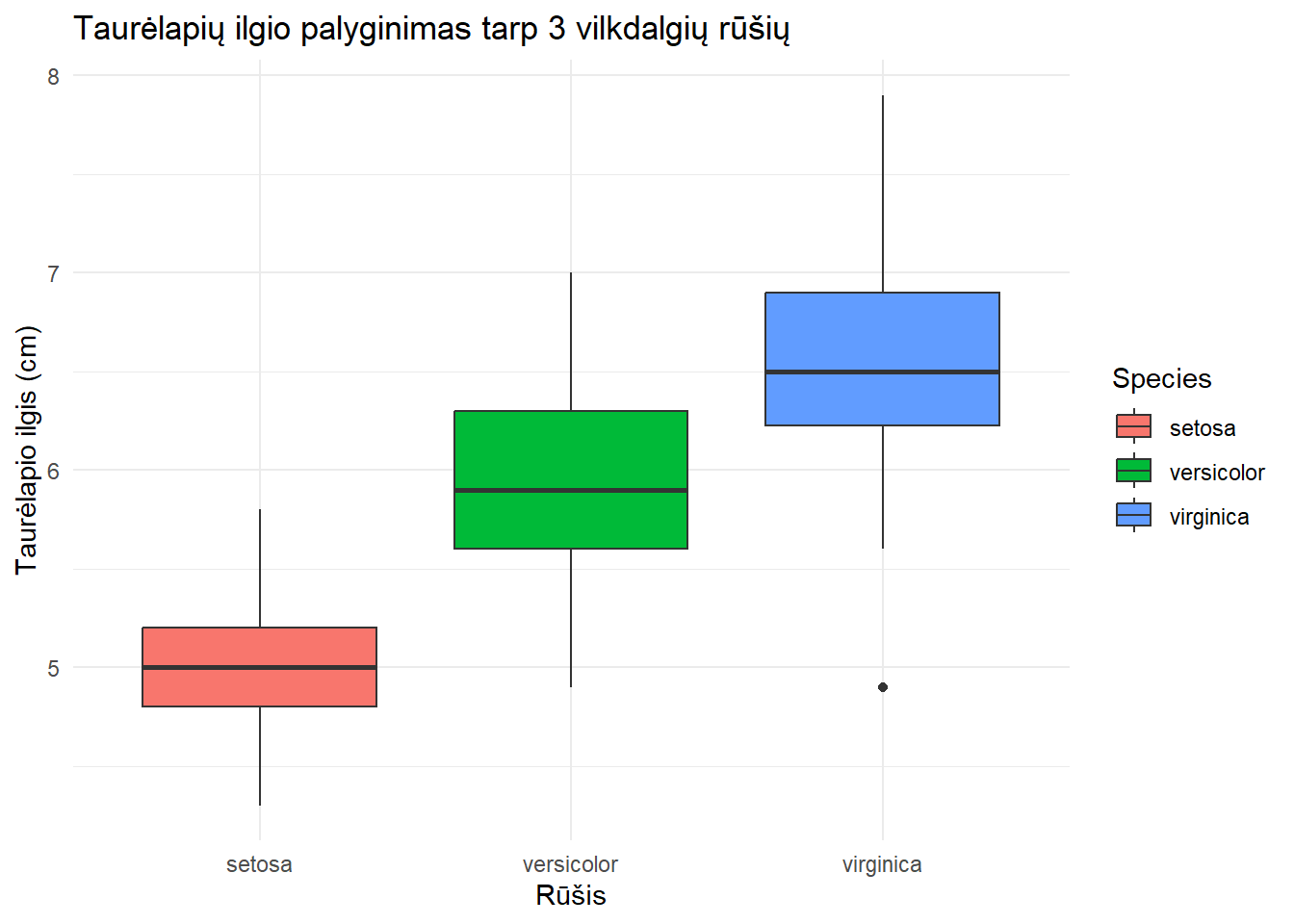
Post-hoc testas nurodo, jog skirtumai buvo tarp visų 3 rūšių tarpusavyje, didžiausias skirtumas buvo tarp virginica ir setosa (vidutiniškai 1,58, 95% PI [1,34-1,83], p < 0,001).
3 vienpusės ANOVA poskoniai
Kai mūsų duomenų rinkinys yra subalansuotas, visi ANOVA tipai duos tokį patį rezultatą. Kai duomenų rinkinys yra nesubalansuotas (viena grupė turi daugiau matavimų negu kitos), rezultatai gali skirtis.
Ar ANOVA buvo tinkamas testas?
Stjudento t-testo tinkamumą praktiniais sumetimais galime numatyti iš anksto, nors teisingas būdas tikrinti būtų toks kaip ir ANOVA atveju. ANOVA turi tris reikalavimus:
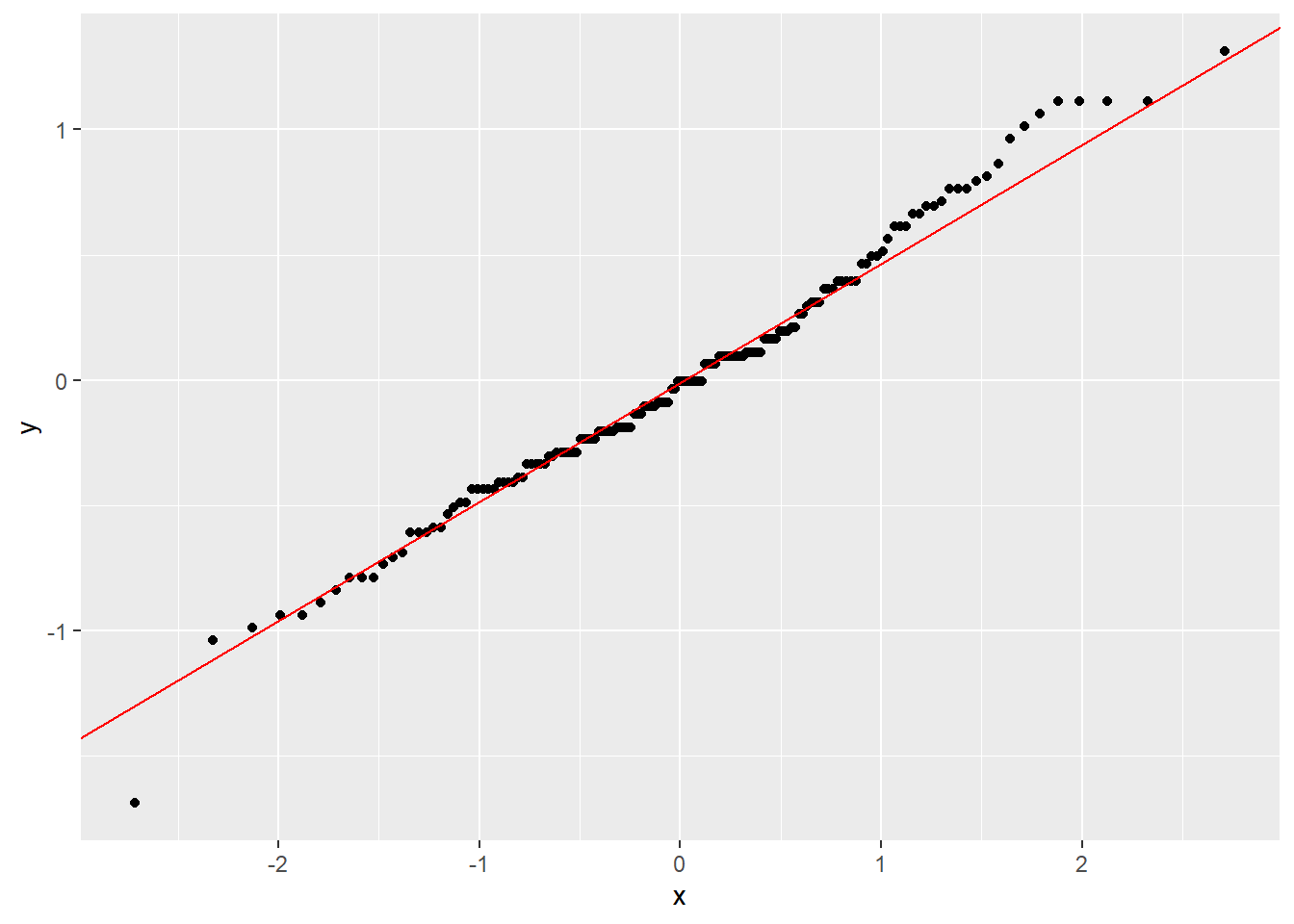
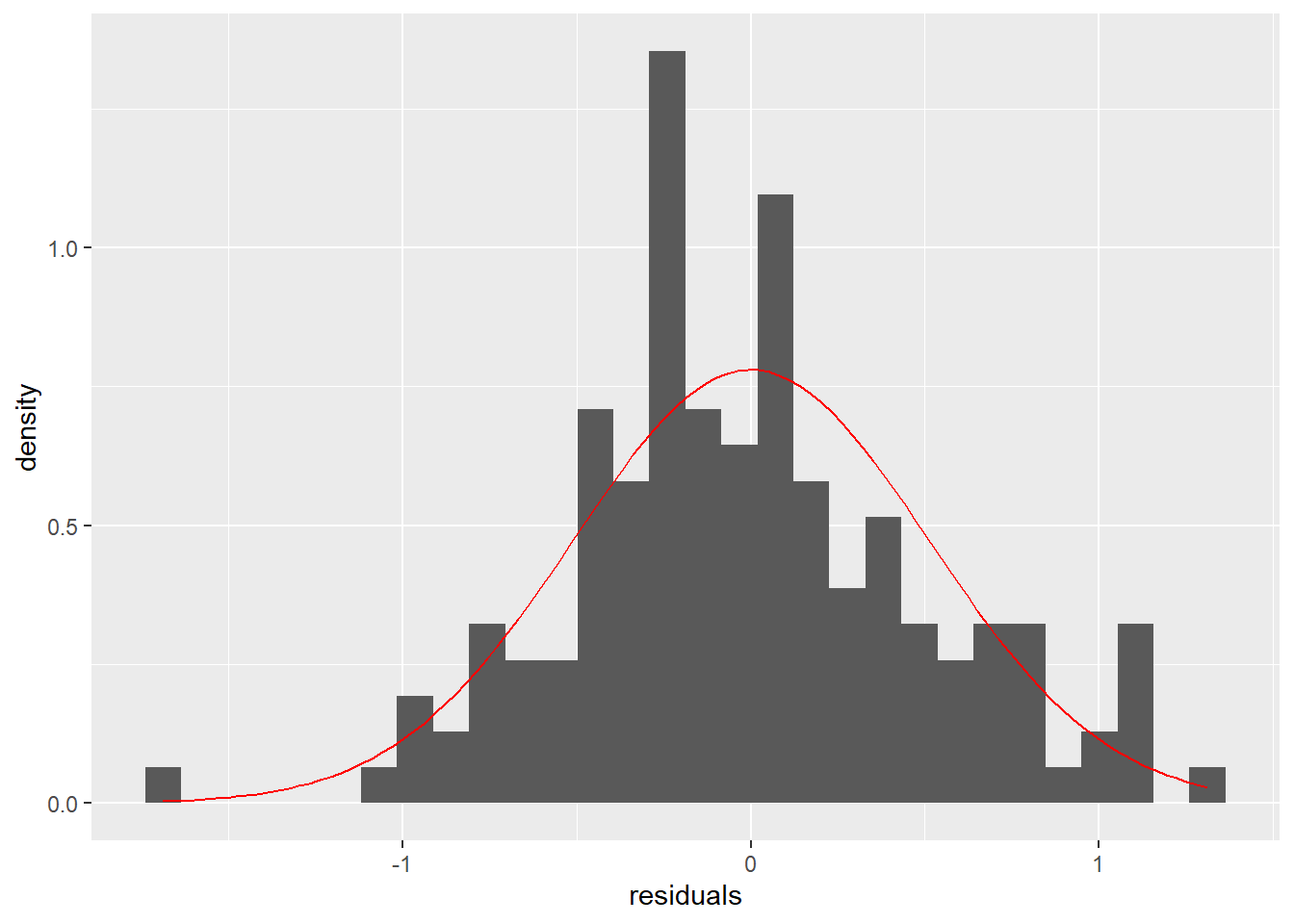
Likutinių verčių (paklaidų) pasiskirstymas turi būti pagal Normalųjį skirstinį. Mažai kas tai tikrina iš tikrųjų ir dažniausiai naudoja histogramas (ok), QQ grafikus (gerai) arba Shapiro-Wilk testą (blogai!)
Homogeniška variacija tarp grupių
Nepriklausomi stebėjimai
Homogeniška variacija
Homogenišką variaciją galima patikrinti su Levene testu, Brown-Forsythe testu arba Bartlett testu, mes panaudosime Levene testą:
leveneTest(my.anova)
Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 2 6.3527 0.002259 **
147
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Pasiskirstymas pagal normalųjį skirstinį
Prieš tikrindami, ar mūsų likutinės reikšmės (nepaaiškinta variacija ANOVA modelio) pasiskirsto pagal normalųjį skirstinį, turime iš ANOVA modelio jas išsitraukti, o tada vizualizuoti arba tikrinti su Shapiro-Wilk testu.
Shapiro-Wilk normality test
data: my.anova.residuals$residuals
W = 0.9879, p-value = 0.2189
Dėmesio
Shapiro-Wilk testas yra pernelyg jautrus dideliems duomenų rinkiniams. Geriau naudoti vizualinius metodus!
Kaip pavaizduoti ANOVA rezultatą?
ggplot(iris, aes(x = Species, y = Sepal.Length, fill = Species)) +geom_boxplot() +labs(title ="Taurėlapių ilgio palyginimas tarp 3 vilkdalgių rūšių",x ="Rūšis",y ="Taurėlapio ilgis (cm)" ) +theme_minimal()